Pythia measures accuracy in LLM responses using the following formula:
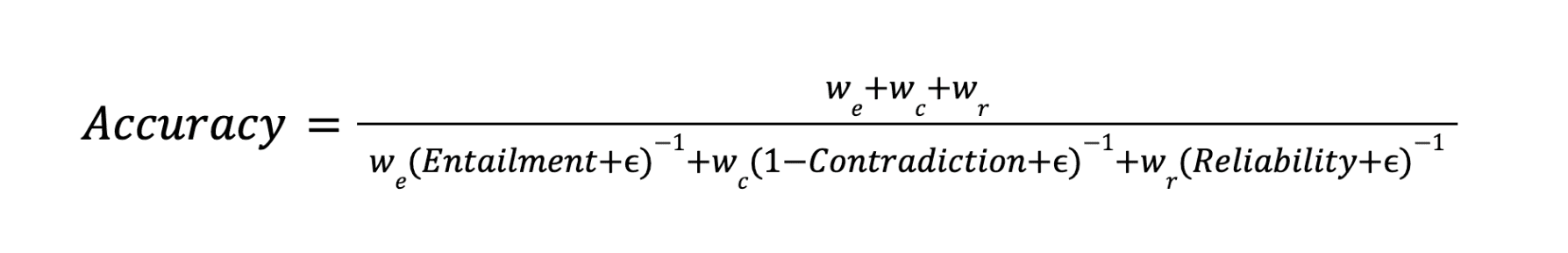
Where,
Entailment: Claims flagged as Entailment
Contradiction: Claims flagged as Contradiction
Reliability: Calculated using external data (i.e., knowledge graphs or RAGs)
The accuracy is calculated as a weighted average where we, wc, and wr are the weights for Entailment, Contradiction, and Reliability.
The accuracy formula provides a comprehensive picture of an LLM’s performance by considering both the presence of correct information and the absence of inaccuracies.
Task Specific Metrics
Entailment
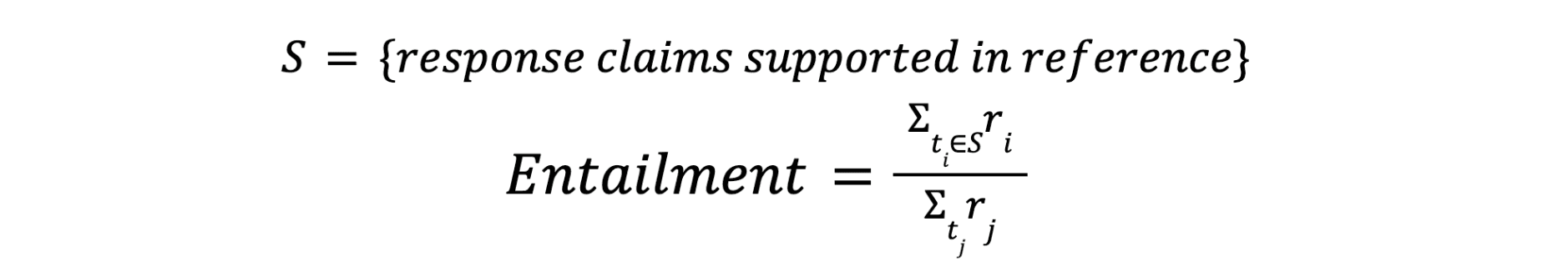
Entailment is computed by comparing LLM generated claims against a set of verified claims in the reference dataset.
The numerator in the Entailment formula sums weights of AI generated claims, claims supported by reference data, and relevancy of associated claim. The denominator sums the weight of all response claims to measure the proportion of Entailment claims.
The weights are assigned based on the relevance of claims to the task at hand. Claims that directly address the task's specific question could be assigned higher weights. Whereas, less relevant claims could be assigned lower weights or excluded from the S set.
This approach ensures that Entailment is directly aligned with the accuracy and relevance of LLM's response.