Insights
Haziqa Sajid
Oct 21, 2024

Learn how AI observability prevents common failures in production, ensuring reliable performance through real-time monitoring and data validation.
AI models are powerful tools but can often behave unpredictably. Here’s a common scenario: You spend months perfecting your model. The F1 score is 88%. You’re confident it’s ready. But when it hits real-world data, everything falls apart. This is a frustrating experience for data scientists, ML engineers, and anyone working with AI models.
So why does this happen? There are many reasons. The quality of your data might be different in production. Or maybe the pipeline design isn’t working as expected. It could be the model itself or how it's managed in real time. Addressing all these challenges is essential to maintaining model reliability and performance.
In this article, we will discuss common issues that make AI models fail in production. We’ll also show you where these issues come from and how to address them.
7 Common Causes of AI Failure in Production
The complexity of AI models and their often opaque decision-making processes create unique challenges in high-stakes environments. Let’s discuss common problems that cause AI models to fail in production:
Data Drift
Data drift occurs when the input data a model encounters in production changes significantly from the data it was trained on. AI models aren’t intelligent enough to adjust to changes in the real world unless they are continuously retrained and updated. Several types of data drift can cause performance drops:
Concept Drift: It occurs when the relationship between the input feature and the target variable changes. For example, a spam detection model might become less effective as spammers change their tactics over time.
Covariate Shift: Here, the input feature distribution changes, while the relationship between those features and the target variable stays the same. For instance, a self-driving car model trained during summer may not perform well in winter when it encounters snowy roads or different lighting conditions.
Prior Probability Shift: This happens when the frequency of certain classes in the data changes. For instance, a credit scoring model trained to assess loan default risk when interest rates were low may not accurately predict default risks under these new conditions. As interest rates rise, more people may begin defaulting on loans, shifting the balance between high-risk and low-risk borrowers.
Mode Collapse
Mode collapse is a common problem in generative models like GANs. It happens when the model produces a narrow range of outputs. A study on GANs used for antiretroviral therapy found that this issue led the model to focus on common clinical practices, limiting its ability to handle unique or less frequent cases.
This lack of variety makes diagnostic models biased and limits their ability to respond to rare scenarios. Therefore, the deployed model can never reliably respond to queries related to exceptional scenarios.
Poor Data Quality
Without clean, balanced, and varied data, AI models struggle to generalize and make accurate predictions. Here’s how poor data can lead to model failure:
Issues with Data Collection: Data collection forms the foundation of AI models, and errors here have long-term impacts. Incomplete or biased data limits the model's ability to generalize. For example, if financial fraud data excludes certain regions, the model will struggle to detect fraud in those locations.
Issues with Data Preprocessing: Poor preprocessing leads to faulty models that don’t perform well outside controlled environments. New data can have issues like missing data, duplication, inconsistencies, and wrongly scaled features that disrupt how your machine learning model works.
Imbalanced Training Data: A study on AI bias revealed that models trained on imbalanced datasets often deliver suboptimal care to certain minority groups. When AI systems learn primarily from majority populations, they may not recognize or appropriately respond to the unique needs of minority groups.
Limited Data Variation: Training data lacking diversity limits the model’s ability to generalize. In production, the model will overfit to narrow contexts, struggling when confronted with new or varied situations.
Hallucinations
Hallucination in AI outputs happens when models like GPT generate information that sounds convincing but is completely incorrect. For instance, a legal AI can confidently provide false legal citations or misrepresent precedents. According to one study, even the best LLMs can hallucinate up to 88% of legal queries.

Professionals who rely on these insights unknowingly make crucial decisions based on hallucination errors. The same risks exist in healthcare, where a hallucination could lead to a misdiagnosis or an inappropriate treatment plan. In both fields, these AI-generated outputs' fluent and authoritative tone makes them even more dangerous, as they can mislead even the experts.
[Webinar: Why Should AI Developers Care about AI Hallucinations]
Failure Due to the Model
AI model failures in production often start with problems in development. These failures happen when key steps like model selection, training, tuning, or verification are not done properly, resulting in poor performance once deployed.
For instance, Booking.com deployed around 150 models to improve click-through rates. However, the team soon discovered that performance issues post-deployment were still a major inhibitor to improving this metric.
Below, we explore how these development issues lead to failures in real-world applications.
Issues with Model Selection: A model’s complexity must match the task and data. For instance, a simple model may fail to detect complex fraud patterns, while an overly complex model can also create problems. Take the case of the team using deep learning to enhance Airbnb's search functionality. The black-box nature of the highly complex neural network overwhelmed the team and led to multiple failed deployments.
Issues with Model Training: Training errors, such as overfitting or relying on unrepresentative data, prevent models from performing well when introduced to new or diverse data. Overfitting locks the model into past patterns, making it less flexible to changes. Failing to account for the actual production environment leads to models that collapse under evolving scenarios.
Issues with Hyperparameter Selection: Incorrect hyperparameter tuning disrupts the model learning process and thus leads to unreliable AI predictions. A high learning rate, for example, can cause the model to miss important patterns, producing inconsistent results. Likewise, the process of selecting the best set of hyperparameters for a machine learning model to maximize its performance is often resource-heavy. The model is likely to fail if the development process doesn’t consider real-world constraints, like energy limits in wireless networks.
Issues with Model Verification: Models that perform well in controlled environments often fail in production when edge cases or broader conditions are ignored. It’s important to verify whether the model meets the right performance metrics to ensure post-deployment success.
Third-Party Models
Relying on third-party AI models can be risky due to the lack of control over how these systems evolve. Changes or updates made by the provider can cause unexpected failures in production. Machine learning systems depend on both software and specialized machine learning settings. As these systems evolve, configuration debt builds up, making the system unstable.
Additionally, adding new data sources after deployment often creates complicated integration code, creating a "pipeline jungle" with messy, error-prone connections. This makes teamwork harder and increases the risk of bugs. Over time, these problems reduce system reliability and scalability, making failures in production more likely.
Malicious Inputs
Adversarial or malicious inputs are like trick questions for AI models. They’re designed to fool AI into making wrong decisions. These inputs seem normal to us but contain small changes that confuse AI systems or lead to complete post-deployment failure. One study found that adversarial examples caused deep neural networks (DNNs) to misclassify malware detection tasks over 84% of the time.
How AI Observability Resolves Common Causes of AI Failure in Production
AI observability helps mitigate common causes of AI failure by monitoring and diagnosing AI behavior in real time. It provides deep insights into how models interact with data, ensuring systems remain accurate, relevant, and reliable across different production environments.
Real-Time Context Validation and Adaptation
AI observability helps by constantly validating incoming data to ensure it matches expected patterns. Advanced input validation tools constantly check whether the data aligns with predefined standards, preventing faulty inputs from reaching the model.
Take predictive maintenance systems in industrial equipment as an example. These AI models monitor sensor data, like temperature and vibration, to predict equipment failures. If there's a sudden spike in temperature due to environmental changes, AI observability validates this sensor data against expected ranges.
If an unusual reading is detected, observability tools flag it as an anomaly, prompting AI engineers to investigate. This allows them to determine whether it's a sensor malfunction or an unexpected environmental factor, preventing larger system failures.
Enhanced Content Monitoring
AI observability enhances content validation by continuously monitoring the quality and relevance of outputs. Output validators ensure that generated content aligns with quality standards and ethical guidelines, detecting and correcting inappropriate or erroneous responses.
In AI-powered customer service chatbots, NLP models occasionally generate inappropriate or irrelevant responses due to ambiguous inputs. AI observability continuously monitors these outputs, ensuring they meet predefined quality and ethical standards. When a problematic response is detected, observability tools immediately flag it, allowing ML engineers to intervene by refining filters or retraining the model.
Managing Data Drift
Observability tools continuously track performance metrics such as feature distribution, target distribution, or population stability index to detect early signs of drift. In fraud detection systems, fraudsters refine their tactics and find new ways to make fraudulent transactions. AI observability continuously monitors transaction data and compares it to historical patterns.
When an anomaly, such as a new payment method, is detected, observability tools trigger immediate alerts. These alerts prompt engineers to take action, allowing them to recalibrate the model, retrain it, or adjust decision thresholds.
Identifying and Rectifying Performance Degradation
Observability provides transparency into model health by monitoring key indicators like accuracy, recall, precision, and response times. This enables teams to take proactive measures, such as model retraining before performance dips significantly affect business outcomes. Continuous monitoring of critical metrics ensures that any performance issues are identified early and addressed, allowing models to maintain operational goals and high performance.
Automation and Continuous Feedback
Traditional monitoring systems suffer from slow, manual feedback loops that delay issue resolution and model adjustments. This process is time-consuming and limits swift responses. AI observability solves this by enabling continuous, real-time feedback. It automatically monitors deployed models, analyzes performance, and makes dynamic adjustments.
With automated insights, AI systems fine-tune parameters, reducing the need for human intervention and accelerating response times. This ensures models are optimized continuously, improving accuracy, stability, and efficiency while minimizing downtime or disruption.
How Pythia Secures AI Success in Production
AI observability is essential for keeping models running smoothly in production. It provides the capability to detect anomalies early, trigger real-time alerts, and prevent minor issues from escalating into costly failures. But to truly optimize AI performance, you need a solution that goes beyond basic monitoring.
That’s where Pythia excels. With advanced features designed to tackle the toughest challenges in AI observability, Pythia empowers your AI systems to perform at their best.
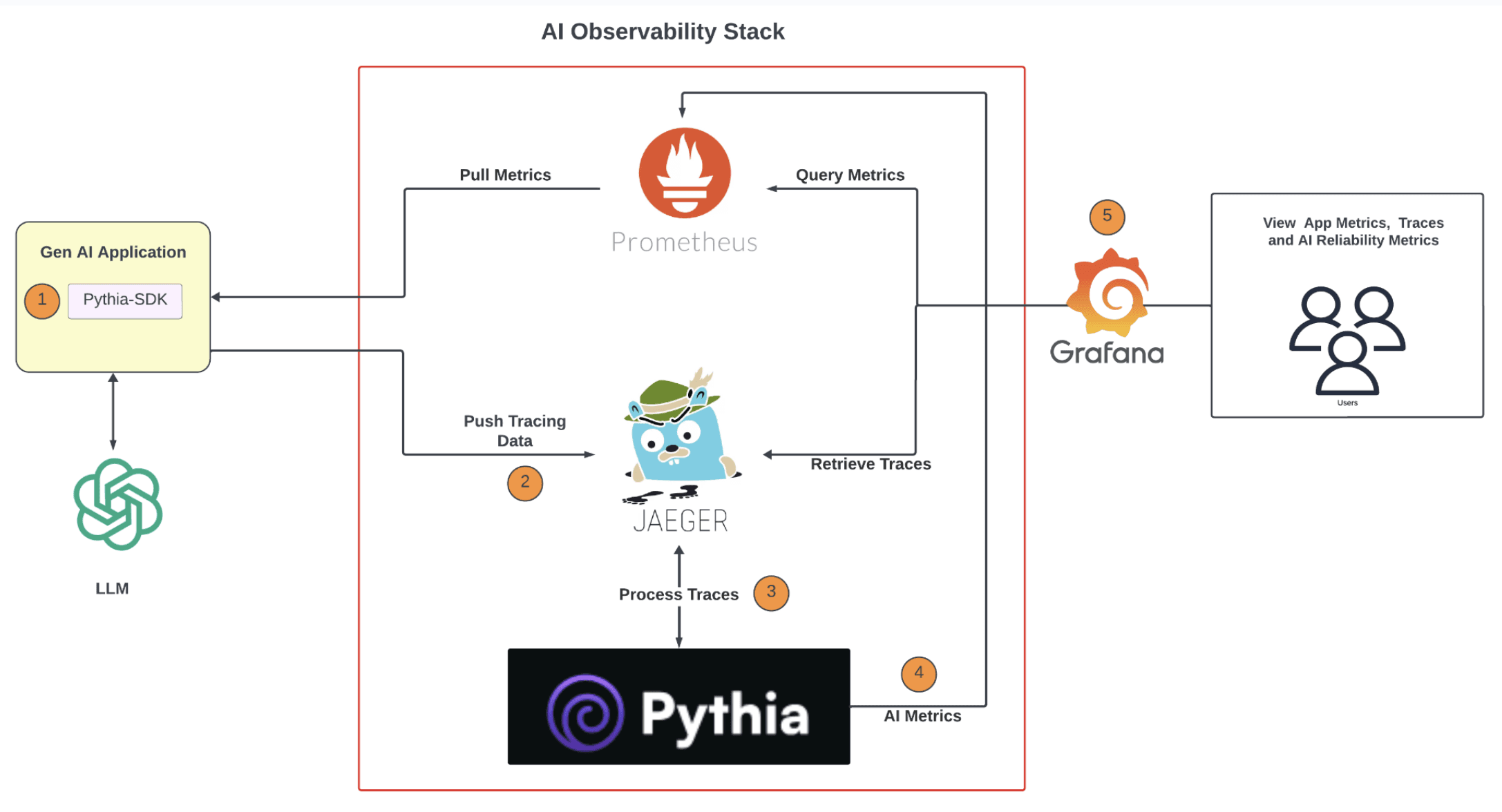
Here's how Pythia can empower your AI systems and ensure they operate at peak performance:
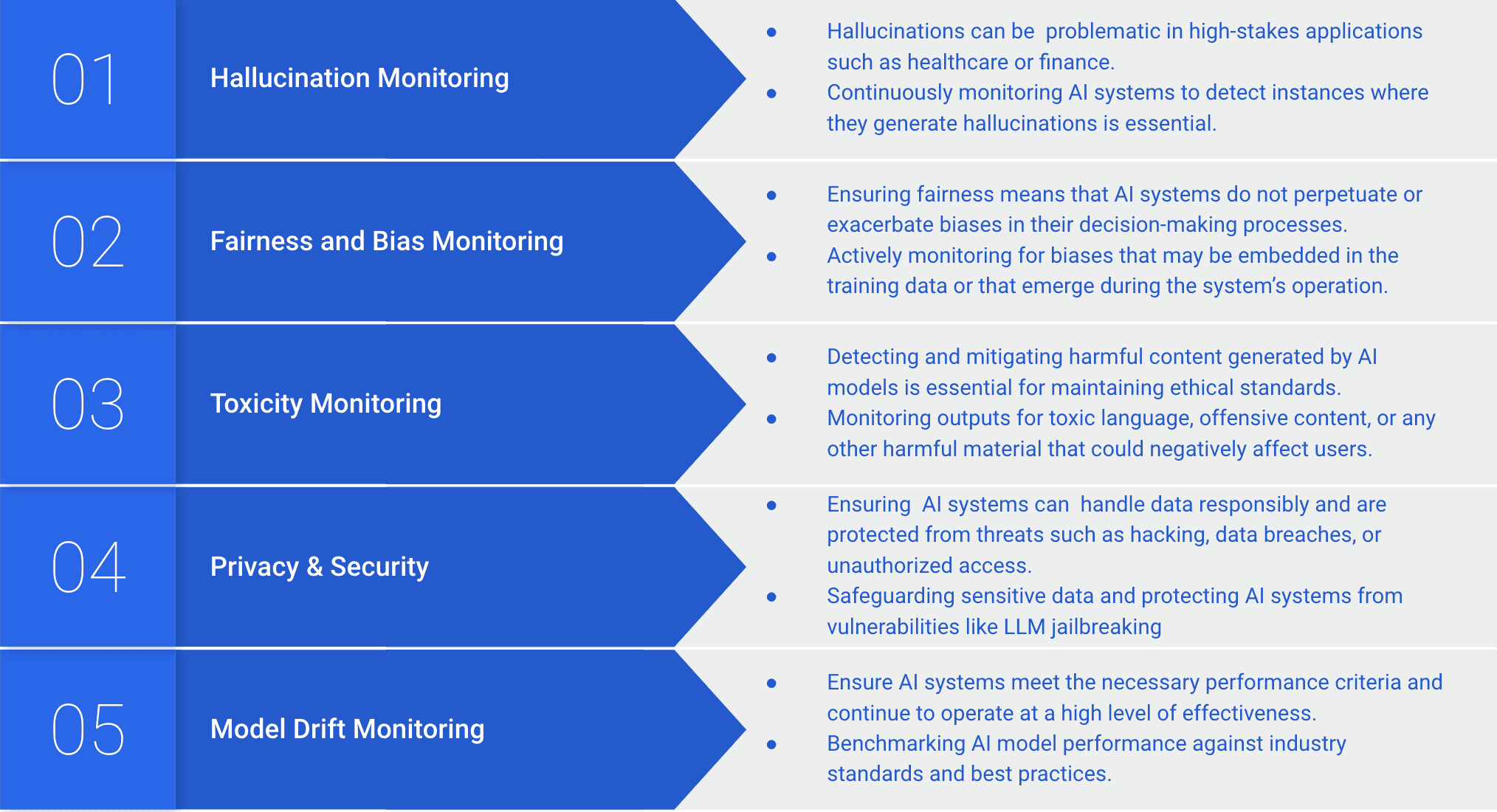
Detect Hallucinations Instantly: Identify inaccuracies in real-time and ensure up to 98.8% LLM accuracy.
Leverage Knowledge Graphs: Ground AI outputs in factual insights with billion-scale knowledge graph integration for smarter, more accurate decisions.
Track Accuracy with Precision: Monitor task-specific metrics like hallucination rates, fairness, and bias to ensure your AI delivers relevant, error-free results.
Validate Inputs and Output: Ensure only high-quality data enters your model, keeping outputs consistent and trustworthy.
Proactively Catch Errors: Spot potential issues like model drift and unexpected data shifts with real-time monitoring and alerts before they escalate.
Secure Your AI: Protect against security threats and ensure outputs are safe, compliant, and free from bias. Implement robust observability practices to safeguard sensitive data and prevent vulnerabilities.
Ready to future-proof your AI systems? Contact us today to learn how Pythia ensures AI success post-deployment!