Insights
Haziqa Sajid
Dec 19, 2024

Did you know that generative AI can hallucinate up to 27% of the time? As AI becomes a key tool for many businesses, this raises an important issue, especially since these AI-generated errors can be tough to spot reliably.
Traditional accuracy metrics like BLEU and ROUGE focus on surface-level matches, such as word overlaps between generated content and reference data. While these metrics can be helpful in some cases, they don’t account for crucial factors like factual accuracy or the true meaning behind the text. On top of that, using LLMs to assess their own accuracy is also problematic since models have their own biases and inaccuracies.
This is where Pythia comes in. Pythia is a system designed to help you detect hallucinations in AI-generated outputs. In this article, we’ll break down how Pythia measures accuracy, examining the methods and metrics used to quantify its effectiveness.
Why Pythia’s Approach Stands Out as an AI Hallucination Detection System
Detecting hallucinations requires a more nuanced approach. One way to tackle this challenge is to break down the content into manageable, verifiable units that can be easily compared against reliable sources.
Pythia offers a sophisticated way to evaluate AI responses by examining the factual consistency of individual claims. Let's take a closer look at what makes this approach effective.
Combining Robust Claim Verification with Flexibility
When you check AI responses for accuracy, the real challenge isn’t just verifying facts. AI tends to bundle misinformation with facts, making it sound more believable. Therefore, hallucination detection systems must identify the subtle ways information can be incorrect. That’s where Pythia stands out.
Instead of viewing a sentence as one big idea, Pythia breaks it into smaller, digestible claims using semantic triplets (subject, predicate, object). Each claim is treated as a standalone unit and verified separately by the model. Since the model verifies each claim independently, it can more effectively detect inaccurate claims within a sentence.

Balanced Between Automation and Accuracy
What makes Pythia unique is its ability to automate the detection process without compromising on accuracy. The system integrates three key components, extraction, classification, and evaluation, into a streamlined, fully automated workflow. This automation allows Pythia to process large volumes of data quickly while maintaining precision.
Modular and Adaptable
Pythia’s modular structure is one of its greatest strengths. It can easily adapt to a variety of AI tasks, whether you’re working with smaller models or larger, more complex systems. Pythia's flexibility ensures it can handle a wide range of applications, from content summarization to use cases like retrieval-augmented question answering (RAG-QA). This adaptability makes it an effective tool for detecting hallucinations across different types of AI models, regardless of size or complexity.
Cost Effectiveness
Balancing performance and cost is a challenge when scaling AI applications. Many high-performing models deliver great results but come with a hefty price tag. Pythia offers similar performance with up to 16 times less cost.
Additionally, the system is flexible enough to handle a variety of tasks, like answering questions and summarizing. Pythia’s design is highly adaptable, which helps businesses adapt it to different needs while keeping expenses in check. Whether you’re managing a large-scale project or a cost-sensitive operation, Pythia delivers the results you need while staying budget-friendly.
How Pythia Measures Accuracy
Pythia takes a structured approach to evaluating the accuracy of AI-generated content by breaking it into smaller, verifiable pieces. By isolating each claim, Pythia can examine individual statements for factual correctness. Let’s see how that works:
AI Response
Pythia analyzes AI responses and breaks them down into relevant claims. Consider the AI-generated response, “Mount Everest is the tallest mountain in the world. It is located in the Andes and was first climbed in the 1950s. However, no climber has ever reached its peak without supplemental oxygen.”
Reference Document
To verify these claims, Pythia compares them to reference materials provided within a specific context. In this case, the reference document states, “Mount Everest is the tallest mountain in the world, located in the Himalayas. It was first climbed in 1953 by Sir Edmund Hillary and Tenzing Norgay.”
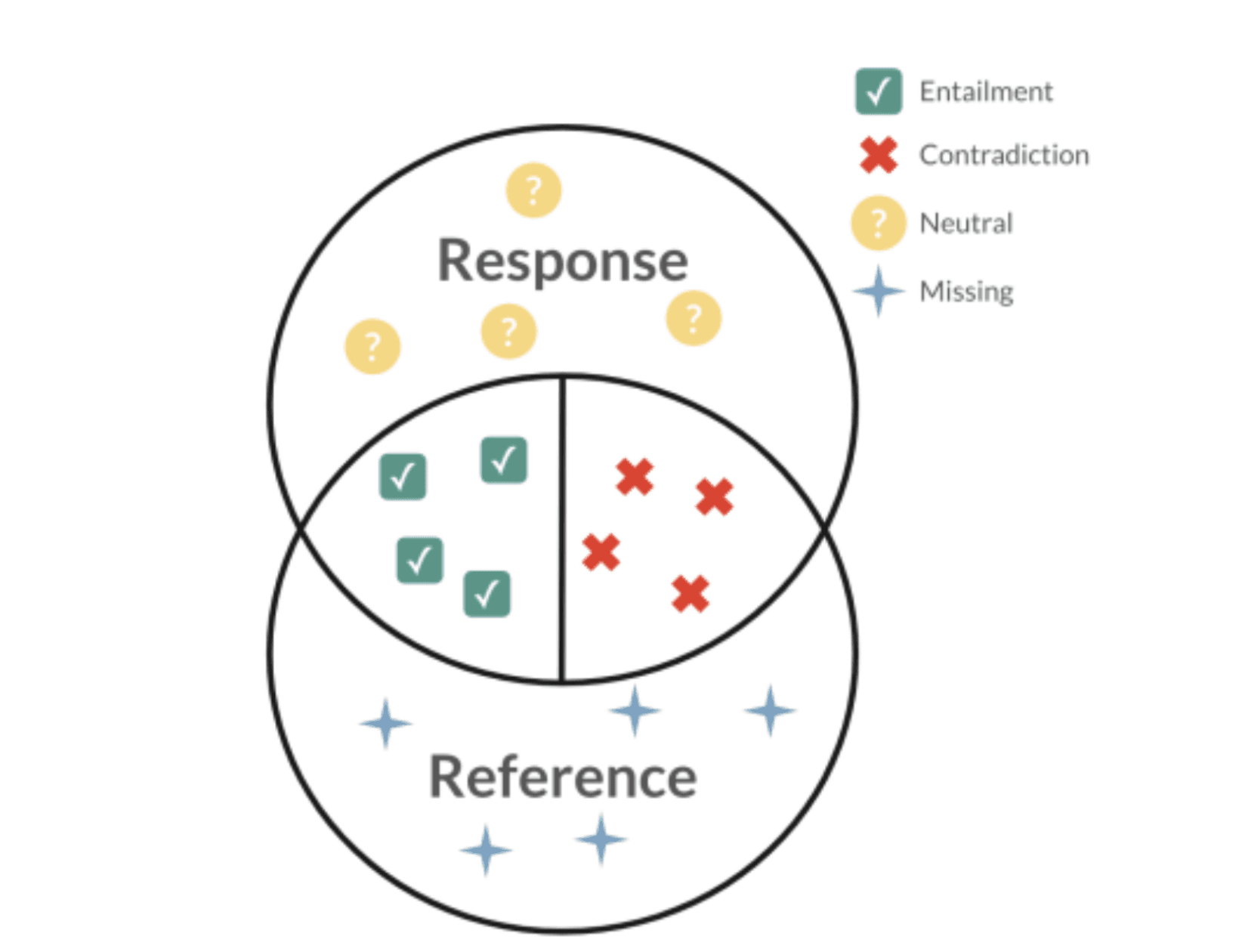
Pythia matches the claims from the AI response with those from the reference document, classifying them into four categories. When a claim is fully supported, it’s marked as entailment. If a claim is refuted, it is flagged as a contradiction. Claims that aren’t directly supported or refuted in the reference document are labeled neutral, while information mentioned in the reference but missing from the AI response is categorized as missing.
The Pythia Algorithm: Step-by-Step Process for Measuring Accuracy
The Pythia algorithm uses a systematic approach to evaluate the accuracy of AI-generated summaries by breaking down content into smaller, verifiable pieces. Here's a detailed look at the step-by-step process using a single claim as an example:

Step 1: Extracting Triples
Pythia's Extractor (E) breaks down both the AI-generated summary (𝑆) and the reference text (𝑅) into triples—simple subject-verb-object statements. These triples represent the key factual claims within the texts. The Model (M) guides the extractor in identifying these claims accurately.
Example:
AI Response: "Mount Everest is the tallest mountain in the world."
Breakdown into Triples:
(Mount Everest, is, tallest mountain in the world)
The AI response contains this simple claim, which is now represented as a semantic triplet: subject (Mount Everest), verb (is), and object (tallest mountain in the world).
Step 2: Classifying Each Triple
The Checker (Ch) compares the extracted triple from the AI response (𝑇𝑠) with the triples from the reference text (𝑇𝑟). In this case, the reference document states: "Mount Everest is the tallest mountain in the world."
Breakdown of Reference Document into Triples:
(Mount Everest, is, tallest mountain in the world)
After comparing the AI-generated triple with the reference text’s triple, the system classifies the claim:
Supported: Since the claim in the AI response matches exactly with the reference document, this triple is classified as supported.
Step 3: Calculating Proportions of Supported and Refuted Claims
The algorithm calculates the proportions of supported claims (𝐸) and refuted claims (𝐶). In this example, since the claim has been classified as supported, it contributes to the proportion of supported claims (𝐸).
Supported claims (𝐸): 1 (for this claim)
Refuted claims (𝐶): 0 (since no refuted claims have been identified)
Step 4: Computing the Factual Accuracy Score
The factual accuracy score (𝐴) is calculated by combining the proportion of supported claims (𝐸) with the impact of refuted claims (𝐶), adjusted by an error tolerance factor (𝜏). For this example:
Since there are no refuted claims (𝐶 = 0), the score is based solely on the proportion of supported claims (𝐸). The higher the proportion of supported claims, the higher the accuracy score.
Step 5: Outputting Results
Pythia produces structured outputs:
𝐶: The classification of this claim is supported.
𝑇𝑠: The extracted triple from the AI response is: (Mount Everest, is, tallest mountain in the world).
𝐴: The overall factual accuracy score is high for this claim, since it aligns perfectly with the reference text.
These outputs provide a clear, quantitative method for assessing the factual accuracy of AI-generated content. In this case, they demonstrate how the claim about Mount Everest is accurate.
Metrics for Assessing Pythia’s Accuracy
Pythia uses a set of key metrics to evaluate the accuracy of AI-generated content. These metrics work together to provide a comprehensive assessment of how well the content aligns with the reference material and the reliability of its claims.
Entailment Proportion
The entailment proportion measures the percentage of claims in the AI-generated summary directly supported by the reference text. A higher entailment score indicates that a larger portion of the summary aligns with the factual evidence in the reference, making the content more reliable.
Contradiction Rate
The contradiction rate quantifies the percentage of claims in the AI-generated summary that the reference text refutes. A higher contradiction rate indicates more inaccuracies, reflecting claims that directly contradict the established facts. The goal is to minimize contradictions in the AI's output.
Reliability Parameter
The reliability parameter is an optional metric that evaluates the quality of neutral claims. A higher reliability score indicates that the summary includes claims that, while not directly referenced, are still factually sound and supported by other reliable data.
If the AI response states, "Climbers use supplemental oxygen at high altitudes," and this claim isn’t directly mentioned in the reference but is generally accepted as true from other reliable sources, it would be classified as a reliable neutral claim.
Factual Accuracy Score (A)
The factual accuracy score (𝐴) is a composite metric that combines the entailment proportion, contradiction rate, and reliability parameter to provide an overall measure of factual alignment between the AI-generated content and the reference. This score is computed using the harmonic mean of the three metrics. This ensures that all factors are given equal weight and that no single metric skews the result.
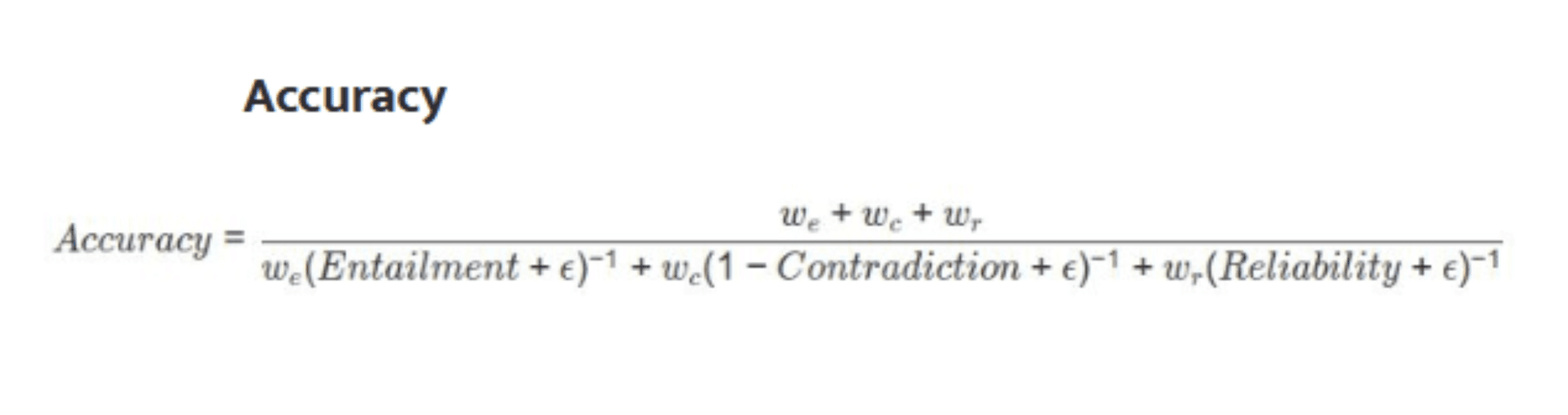
A higher accuracy score reflects better overall factual consistency with the reference text, while a lower score indicates discrepancies and factual inaccuracies.
Pythia’s Role in AI Hallucination Detection and Future Potential
Pythia is a powerful tool designed to improve the accuracy and reliability of AI-generated content. It uses a systematic approach to detect hallucinations, helping reduce the risks of misinformation.
Pythia plays a key role in preventing misleading or incorrect information in industries like healthcare, finance, law, and scientific research, where accuracy is crucial. It builds trust in AI systems by classifying claims and measuring their factual accuracy.
As AI technology evolves, Pythia’s ability to verify factual accuracy will only grow in importance, offering major benefits in industries where precision and trust are essential. Don’t let misinformation impact your AI applications.
Activate your Pythia trial now and keep your content accurate and reliable.