Learning Resource
Haziqa Sajid
Jun 27, 2024

Explore the practical applications of Pythia and how it addresses LLM contexts to achieve reliable AI.
Pythia is a powerful hallucination detection tool that detects misinformation in large language model (LLM) outputs and ensures reliable interaction between AI and humans. It helps LLM developers and companies reduce error rates in LLM outputs, avoid spending millions on corrective procedures and legal liabilities, and maintain a good reputation among users.
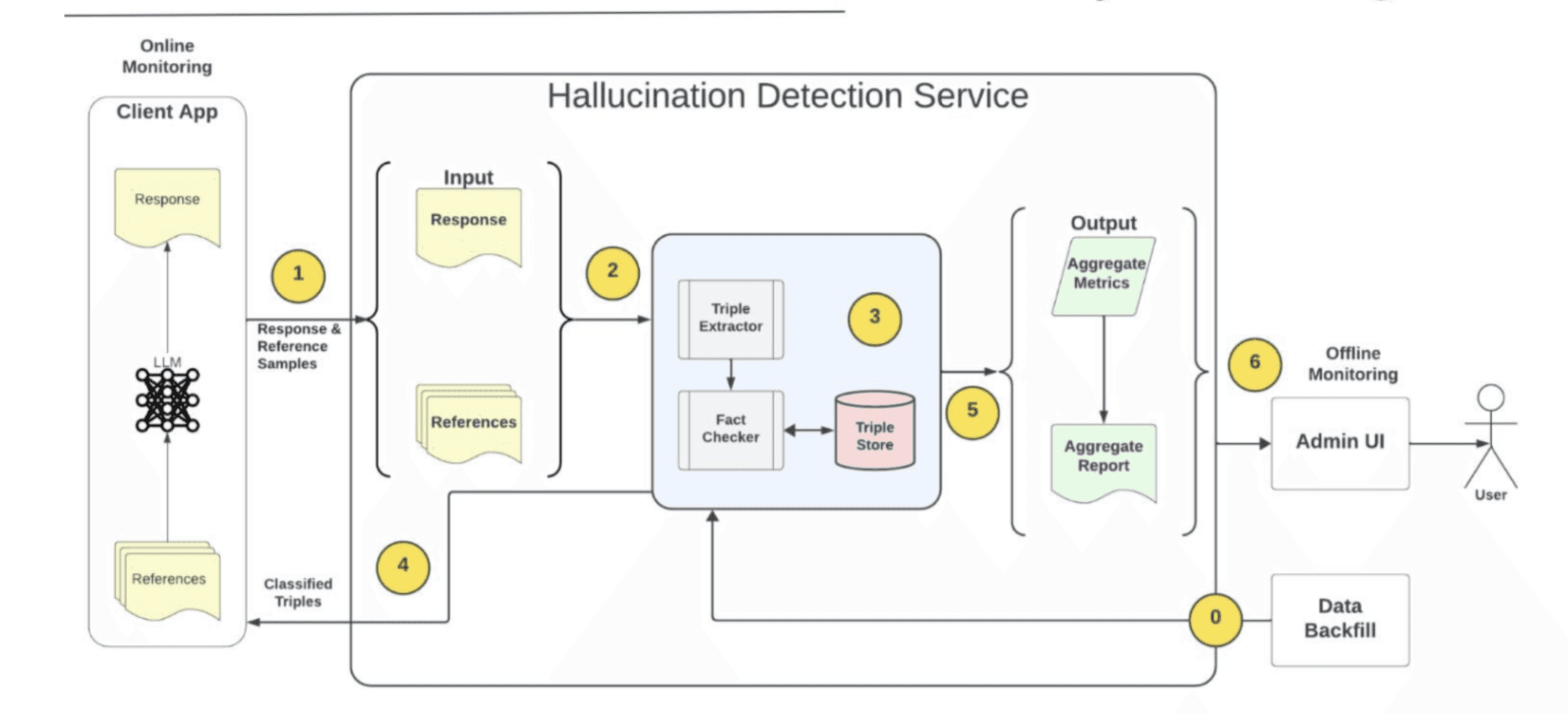
Pythia’s unique methodology consists of claim extraction and categorization, real-time monitoring, and knowledge graph integration to verify LLM response against legitimate sources of information. This enables Pythia to easily integrate with chatbots, RAG-based systems, and text summarization tools for real-time monitoring. It flags inappropriate outputs and generates a detailed audit report highlighting the tool’s strengths and weaknesses.
This feature allows developers and subject matter experts to work towards improving LLMs to mitigate hallucinations and serve their original purpose.
Let’s explore some of the Pythia use cases and how they address the LLM contexts in the real world.
Pythia Use Cases
Here are the three common use cases of Pythia:
Chatbots
Healthcare chatbots use natural language processing (NLP) to assist patients with medical support, such as assessing symptoms, appointment scheduling, or providing mental support. These chatbots are trained on medical databases to learn and improve their accuracy. Based on their learning, chatbots analyze user input and generate a relevant response for the user.
Pythia integrates within healthcare chatbots to monitor LLM responses against user queries. It measures the accuracy and alignment of the response with the user query by continuously monitoring LLM activities. Whenever a user asks a question, and LLM generates a response, Pythia extracts knowledge triplets from the response and chatbot databases. It then compares knowledge triplets against each other to generate an LLM audit report.
RAG (Retrieval-Augmented Generation) systems
RAG systems use an additional knowledge base beyond the training data, adding an extra LLM claim verification layer. However, RAG systems can still generate nonsensical outputs due to the knowledge base's existing bias or limited relevant resources.
Like chatbots, Pythia integrates with RAG systems to detect hallucinations in LLM responses. Once integrated, it continuously monitors the system performance in real-time using accuracy and task-specific metrics and highlights the performance in Pythia UI. This enables LLM developers and stakeholders to make immediate corrective decisions and improve user experience.
Text Summarization
Healthcare text summarization involves condensing large texts, such as medical reports or clinical documents, into shorter summaries while retaining the essential information. Several machine learning and statistical methods assist LLMs in generating summaries of large, complex texts.
Accurately processing medical terminology, protecting sensitive information, and preserving information are common challenges text summarization systems face. These challenges result in generating inaccurate summaries or losing information and the meaning of the actual text.
Pythia effortlessly compares summarization tool outputs with its knowledge base and ensures the generated summary doesn’t disregard essential information. It can also use a knowledge graph to ensure accurate, relevant, and up-to-date claims.
Pythia’s ability to integrate with LangChain makes it a go-to hallucination detection tool for LLM developers. This integration allows developers to leverage Pythia's full potential with effortless interoperability. It also ensures RAG developers can access a comprehensive toolkit for developing reliable AI.
Pythia’s Ability to Address LLM Contexts
LLM context refers to the information an LLM uses to generate outputs. The contexts vary with LLM applications such as chatbots or RAG; understanding them is essential for effectively interpreting outputs.
What are the three LLM contexts?
Below are the three LLM contexts and how they differ:

Zero Context
Zero context refers to user prompts that ask for factual knowledge and don’t include any contextual information. LLM's response to these prompts only relies on user queries and general knowledge of LLM based on its training.
For example, if a user asks, “What is stevia used for?”, the model answers, “Stevia is a sweetener and sugar substitute derived from the leaves of the Stevia rebaudiana plant. It is known for its intensely sweet taste without the calories of sugar.”
Noisy Context
Noisy context refers to user prompts where the context includes irrelevant or misleading information. This can confuse the model and potentially degrade the quality or accuracy of its responses.
Here’s an example of a noisy context prompt, “I've had a terrible headache for two weeks, and I'm really worried I have a brain tumor. I read online that headaches are a major symptom.”
Accurate Context
Accurate context means the user query is relevant, clear, and directly related to the task or query. This helps the model generate precise and contextually appropriate responses.
For example, “I secured 3 As and 2 Bs in my A-level exams. However, I found that the admission requirement for University X is 4 As. What are some alternative options for me that are also in high demand and popular?”
How does Pythia address the three LLM contexts?
A robust LLM should be able to address the three contexts discussed above. An AI reliability solution should be able to assess an LLM’s response to accommodate the contexts.
Chatbots as Zero Context
Chatbots often encounter zero-context queries for quick medical assistance. These queries generally revolve around factual knowledge, and chatbots use their training databases to generate a response. However, if the user prompt is unfamiliar to the chatbot, it can generate nonsensical outputs.
Pythia monitors chatbot responses to detect when the chatbot fails to generate relevant outputs. Here’s how it works:
A user enters a query into the chatbot.
The chatbot generates an answer.
Pythia compares the answer to the chatbot’s knowledge base.
Pythia generates an audit report based on the comparison.
As a result, Pythia highlights when the chatbot deviates from its knowledge base and creates nonsensical outputs. For example, if a user asks, “What is subrogation in insurance?” when the chatbot is designed to assist insurance clients with customer support, it might generate an irrelevant output. When Pythia compares the output with the chatbot’s database, it identifies the irrelevant output and flags it. Finally, chatbot developers can debug the logic and improve its performance depending on their objectives.
This allows chatbot developers and companies to provide a safe interaction between chatbots and end-users.
Here’s how to integrate Pythia in chatbots for zero-context LLM hallucination detection:
Develop a chatbot.
Install Wisecube and authenticate Pythia.
Integrate Pythia into your workflow.
Detect real-time hallucinations in chatbot responses.
RAG Systems as Noisy Context
RAG systems rely on external information sources to generate responses. Therefore, the accuracy of RAG systems is highly dependent on the accuracy of external sources. However, Pythia can compare RAG-based systems’ claims through an extensive knowledge graph, adding an extra verification layer.
RAG systems often encounter noisy user prompts, and to ensure the reliability of responses, they must be able to understand user context. Unlike traditional hallucination detection tools, Pythia extracts claims from AI-generated output and knowledge bases as knowledge triplets. Knowledge triplets divide a sentence into <subject, predicate, object> format, revealing the relationship between subject and object to the RAG system.
For example, if a user asks, “Leonard McCoy underwent a Prostate TRUS biopsy last week. He now feels a severe headache and a racing heartbeat. Please tell me risk-free solutions to ease his pain.” to a RAG system, here’s how Pythia dissects this prompt using knowledge triplets:
Subject: Leonard McCoy Predicate: underwent Object: Prostate TRUS biopsy
Subject: Leonard McCoy Predicate: has Object: severe headache and raced heartbeat
This way, Pythia can interpret user concerns and detect the relevancy of the response through claim comparison. Since conventional methods don’t break sentences into this format, they only capture keywords like “Prostate TRUS biopsy” and generate a general result.
Based on the claim comparison, Pythia categorizes them into “entailment”, “neutral”, “contradiction”, and “missing facts”. Finally, it generates an audit report, highlighting the performance of RAG systems so you can take necessary measures to improve its performance. Therefore, if your RAG system generates a general output without understanding the user query, Pythia helps you identify that in real time and deliver a better experience to end-users.
Here’s how to integrate Pythia in RAG systems for noisy context LLM hallucination detection:
Develop a RAG system.
Install Wisecube and authenticate Pythia.
Integrate Pythia into your workflow.
Detect hallucinations in RAG outputs.
Head over to Pythia docs for a detailed guide on integrating Pythia in RAG systems.
Text Summarization as Accurate Context
Text summarization software usually processes queries providing clear information about the user's needs. This can include a summary of a detailed medical report, focusing on the key findings and recommendations. As a response, the software condenses large volumes of medical text, such as reports or clinical documents, into shorter summaries that retain the essential information.
With the rise in AI content detectors, users sometimes demand summarization software to generate a human-like summary. This might confuse AI, resulting in missing information in the generated summary. Therefore, accurate processing of medical terminology, protecting sensitive information, and preserving the meaning of the original text are the challenges in this context.
Here’s how Pythia helps text summarization software to generate accurate summaries:
Knowledge triplets break down the relationship between phrases and sentences.
Claim comparison ensures the summary preserves the original message.
Optional knowledge graph check adds an extra verification layer.
For example, if a user enters a research paper for summarization, the software generates a summary, and Pythia detects this activity in real time. With the help of knowledge triplets, Pythia extracts the following key claims from the medical report:
Subject: Eigenvalues of the matrix and the stability of the system Predicate: are Object: significantly correlated
Subject: Theorem Predicate: shows Object: 95% confidence interval
However, the software overlooks the second claim in the summary. Pythia will immediately flag it as “missing facts”, guiding the developers to look into the underlying errors.
Similar to the other use cases, integrating Pythia in text summarization software for accurate context LLM hallucinations:
Develop a text summarization software.
Install Wisecube and authenticate Pythia.
Integrate Pythia into your workflow.
Detect hallucinations in AI-generated summaries.
Continuous online monitoring and comparison of LLM claims and references identify when an LLM fails to generate appropriate responses for all LLM contexts. This includes examining the relevancy of responses against user queries, assessing the accuracy of claims, and giving insights into the model’s limitations.
Pythia UI displays model performance through visualizations and sends SMS alerts whenever an event occurs so you can track the LLM performance and your spending.
Start using Pythia today to detect real-time hallucinations in your LLMs and improve their performance for reliable outcomes.